Sequence Sharding: How to train long-context LLMs
Thanks to Yi Wang and Hanzhi Zhou for valuable feedback on this post.
Large language models (LLMs) face fundamental scaling limits due to the computational and memory costs of self-attention over long input sequences. As context lengths grow from thousands to millions of tokens, the quadratic complexity of attention becomes a critical bottleneck. Sequence sharding (also known as sequence parallelism) has emerged as a key strategy to overcome this limitation by distributing sequences across multiple devices. This blog post reviews the key developments in this area, along with technical insights into how these approaches work and when to use them.
I will use the following notations throughout this post:
B: Batch size.T: Query length.S: Key/Value length (same asTin self-attention).N: Number of KV heads.G: Number of groups (G * Nis the number of query heads).H: Head dimension.D: Model dimension (equal toG * N * H).F: Hidden dimension in MLP (usually equal to4D).P: Number of partitions.
Early Developments
An early precursor was introduced in NVIDIA’s Megatron-LM (Korthikanti et al., 20221), which applied a form of sequence parallelism to reduce activation memory alongside tensor parallelism. This approach partitioned certain operations (e.g., dropout and layer normalization) along the sequence dimension and used communication operations (all-gather and reduce-scatter) instead of storing full-size activations. However, this method did not distribute the attention computation itself—each attention operation still required the full sequence on each device.
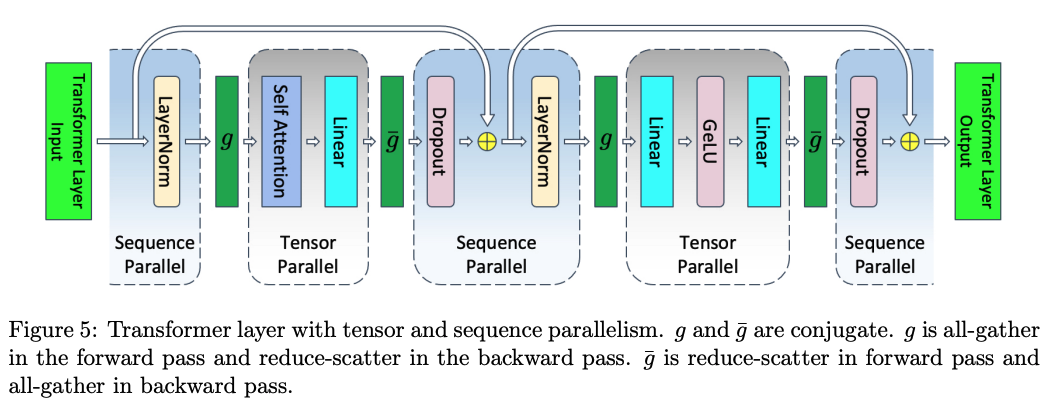
From KV All-Gather to Ring Attention
A significant step toward sequence sharding came from Li et al. 20212, who proposed Ring Self-Attention (RSA), an algorithm to compute attention across partitioned sequences on multiple GPUs. Each input sequence is split into chunks, with each GPU processing one chunk. During self-attention computation, GPUs exchange key/value information in a ring topology, enabling every query to attend to all keys/values across the full sequence.
To understand RSA more deeply, here I provide an alternative interpretation from a collective matrix multiplication perspective (Wang et al. 20233): to perform self-attention on Q: [B, T/P, G, N, H], K: [B, S/P, N, H], V: [B, S/P, N, H] sharded along the sequence dimension over P devices, the naive approach would perform an all-gather on K and V respectively, followed by local matrix multiplication to obtain the context [B, G, N, T/P, S] and the final output [B, T/P, G, N, H]. However, this approach is suboptimal because it doesn’t allow overlapping communication with computation.
Alternatively, one can perform matrix multiplication on the local chunk of Q: [B, T/P, G, N, H] and K: [B, S/P, N, H], producing a result of shape C: [B, G, N, T/P, S/P]. Simultaneously, the algorithm permutes K in a ring topology to obtain the next chunk locally. This process repeats for P iterations so that each device accumulates a local context of shape [B, G, N, T/P, S] (the same algorithm applies for the output [B, T/P, G, N, H]). Now we have arrived at the exact RSA algorithm.
In this view, RSA is basically an application of collective matrix multiplication in self-attention with sequence parallelism. The communication cost in the attention layer equals that of the naive all-gather: 2 (P-1) * BTNH / P per device. No communication is required in the MLP layer. The comparison between sequence parallelism and tensor parallelism is summarized in the following tables.
Communication cost:
| Sharding | Attention Comm. | MLP Comm. |
|---|---|---|
| Sequence Parallelism (RSA) | 2 (P-1) * BTNH / P | 0 |
| Tensor Parallelism (Megatron-LM) | 2 (P-1) BTD / P | 2 (P-1) BTD / P |
Memory cost:
| Sharding | Attention Weights (QKVO) | Peak Attention Activations (fwd) | MLP Weights | Peak MLP Activations (fwd) |
|---|---|---|---|---|
| Sequence Parallelism (RSA) | 2D(G+1)NH | (BTD+2BTNH) / P + BGNT^2 / P | 2DF | BTD/P + BTF/P |
| Tensor Parallelism (Megatron-LM) | 2D(G+1)NH/P | 2(P-1)BTD / P | 2DF / P | BTD + BTF/P |
Building on the ring-based concept, Liu et al. 20234 introduced Ring Attention with important enhancements over Li et al. 20212. Ring Attention divides the sequence into fixed-size blocks and arranges GPUs in a ring topology. Each GPU processes one block of the sequence at a time. Crucially, as each GPU finishes computing attention on its block, it passes its key-value blocks to the next GPU while simultaneously receiving the next set of key-values from its neighbor. Ring Attention can be viewed as a distributed extension of blockwise memory-efficient attention, similar to FlashAttention’s approach of fusing QKV matrix multiplications for efficiency. This results in peak memory during attention of (2BTD+2BTNH)/P + BGNT^2 / P^2.
Brandon et al. 20235 identified a workload imbalance issue specific to causal (autoregressive) models. In causal self-attention, each token only attends to earlier tokens, creating a triangular compute pattern where earlier blocks perform more work than later ones. With naive sequence splitting (where each GPU receives a contiguous range of tokens), the GPU holding the first tokens performs the most attention work, while the GPU with the last tokens performs the least, leading to inefficiency. Striped Attention addresses this by assigning each GPU a “stripe” of the sequence rather than one contiguous block. For example, with 4 GPUs and a sequence of length N, instead of GPU1 receiving tokens 1..N/4, GPU2 receiving N/4+1..N/2, etc., each GPU receives every 4th token (GPU1 gets tokens 1,5,9,…; GPU2 gets 2,6,10,…, and so on). This interleaving ensures every GPU handles a mix of early and late positions, equalizing the attention computation workload per GPU.

By addressing the triangular attention imbalance, Striped Attention makes sequence sharding more efficient for autoregressive LLMs (such as GPT-style models). Notably, it does not change the asymptotic memory scaling (which remains linear with the number of devices, same as Ring Attention), but it improves throughput and hardware utilization in the common scenario of causal training.
All-to-All Sequence Sharding
In 2023, Microsoft’s DeepSpeed team released DeepSpeed-Ulysses (Jacobs et al. 20236). Ulysses partitions input sequences across devices and uses collective all-to-all communication to perform attention computations efficiently. Each GPU holds a segment of the Q, K, V tensors (similar to ring-based approaches2 4 5), but instead of simple ring communication, Ulysses utilizes optimized all-to-all operations to gather the required tokens for attention. A key advantage of Ulysses is that its communication cost is inversely proportional to the number of sequence shards (SP degree).
Communication cost:
| Sharding | Attention Comm. | MLP Comm. |
|---|---|---|
| Sequence Parallelism (Ulysses) | BTD / P | 0 |
Memory cost:
| Sharding | Attention Weights | Peak Attention Activations (fwd) | MLP Weights | Peak MLP Activations (fwd) |
|---|---|---|---|---|
| Sequence Parallelism (Ulysses) | 2D(G+1)NH | (3BTD) / P + BGNT^2 / P | 2DF | BTD/P + BTF/P |
One known limitation is that Ulysses requires the SP degree to be ≤ the number of attention heads. This constraint arises from how the all-to-all communication is structured across attention heads. In practice, this limitation caps the maximum sequence parallelism for a given model architecture (for example, a model with 64 attention heads can shard the sequence into at most 64 partitions).
Fang & Zhao et al. 20247 observed that Ulysses and Ring Attention are not mutually exclusive and can be combined in a hybrid 4D parallelism strategy. They proposed a Unified Sequence Parallel (SP) approach that integrates Ulysses-style all-to-all communication with Ring-style peer-to-peer overlapping. By combining these approaches, the unified SP can use all-to-all communication in regimes where it’s optimal and switch to ring overlapping in others.
Sequence Sharding for Inference
Yang et al. 20248 demonstrated that sequence parallelism is also beneficial for LLM inference, particularly during the prefill stage where computation dominates. Sequence parallelism’s advantage increases when KV heads are fewer than Q heads (e.g., in Grouped Query Attention), because the volume of K/V exchange is smaller than the full activation transfer required in Megatron-style tensor parallelism. Empirically, sequence parallelism outperforms tensor parallelism when batch size is small and context length is long. Arctic Ulysses9 adapted the Ulysses approach6 for long context inference by replacing all-reduce communications with two all-to-all communications whose communication volume decreases with SP degree. This demonstrates that the hybrid 2D Ulysses-TP approach achieves both memory efficiency and scalable performance for low-latency long context inference.
Conclusion
Sequence sharding has evolved from a simple memory optimization technique to a sophisticated family of algorithms that enable training and inference on sequences with millions of tokens. The progression from Megatron-LM’s basic sequence parallelism to Ring Attention’s distributed computation, Striped Attention’s load balancing, and Ulysses’s optimized communication patterns demonstrates the rapid innovation in this space.
The choice between different sequence sharding approaches depends on several factors: hardware topology, model architecture (especially the number of attention heads), sequence length, batch size, and whether the workload is training or inference. As context lengths continue to grow and new model architectures emerge, sequence sharding will remain a critical technique for scaling LLMs to handle the long-context applications that define the next generation of AI systems.
-
Reducing Activation Recomputation in Large Transformer Models. Vijay Korthikanti, Jared Casper, Sangkug Lym, Lawrence McAfee, Michael Andersch, Mohammad Shoeybi, and Bryan Catanzaro. arXiv:2205.05198 (2022) ↩︎
-
Sequence Parallelism: Long Sequence Training from System Perspective. Shenggui Li and Fuzhao Xue and Chaitanya Baranwal and Yongbin Li and Yang You. arXiv:2105.13120 (2021) ↩︎ ↩︎ ↩︎
-
Overlap Communication with Dependent Computation via Decomposition in Large Deep Learning Models. Shibo Wang, Jinliang Wei, Amit Sabne, Andy Davis, Berkin Ilbeyi, Blake Hechtman, Dehao Chen, Karthik Srinivasa Murthy, Marcello Maggioni, Qiao Zhang, Sameer Kumar, Tongfei Guo, Yuanzhong Xu, and Zongwei Zhou. ASPLOS ‘23. (2023) ↩︎
-
Ring Attention with Blockwise Transformers for Near-Infinite Context. Hao Liu, Matei Zaharia, Pieter Abbeel. arXiv:2310.01889 (2023) ↩︎ ↩︎
-
Striped Attention: Faster Ring Attention for Causal Transformers. William Brandon, Aniruddha Nrusimha, Kevin Qian, Zachary Ankner, Tian Jin, Zhiye Song, Jonathan Ragan-Kelley. arXiv:2311.09431 (2023) ↩︎ ↩︎
-
DeepSpeed Ulysses: System Optimizations for Enabling Training of Extreme Long Sequence Transformer Models. Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Shuaiwen Leon Song, Samyam Rajbhandari, Yuxiong He. arXiv:2309.14509 (2023) ↩︎ ↩︎
-
A Unified Sequence Parallelism Approach for Long Context Generative AI. Jiarui Fang, Shangchun Zhao. arXiv:2405.07719 (2024) ↩︎
-
Context Parallelism for Scalable Million-Token Inference. Amy Yang, Jingyi Yang, Aya Ibrahim, Xinfeng Xie, Bangsheng Tang, Grigory Sizov, Jeremy Reizenstein, Jongsoo Park, Jianyu Huang. arXiv:2411.01783 (2024) ↩︎
-
Low-Latency and High-Throughput Inference for Long Context with Sequence Parallelism (aka Arctic Ulysses). Snowflake. https://www.snowflake.com/en/engineering-blog/ulysses-low-latency-llm-inference/ ↩︎